
I mitt inlägg Vad är Allfalytics skrev jag väldigt kort om modellens resultat förra säsongen. Jag tänkte att det är dags att gå in närmare på det. Vi ska kolla lite snabbt på utvecklingen för modellaget i jämförelse både med mitt egna lag men också i relation till ledaren, topp 100 och topp 1000. Efter det är det dags att dyka in på modellens prestation i allmänhet, titta lite närmare på några spelare och förhoppningsvis också hitta några svagheter. Eventuella svagheter där modellen har fel kan vara bra att ha med sig in i nuvarande säsong för att inte bli lurad helt enkelt.
Modellaget
Parallellt med mitt egna lag lät jag också modellen styra ett helt automatiserat. Modellens förväntade poäng blir input till ett linjärprogrammeringsproblem som tittar 8 veckor framåt och hittar de optimala besluten givet att modellens förväntade poäng är den absoluta sanningen. Vi behöver inte gå djupare in på det, men om du är intresserad av att lära dig mer om detta kan jag rekommendera Sertalp B. Çays Youtube-kanal där du kan se tutorials för att göra precis detta i Fantasy Premier League med FPL Review som input. Hans twitterkonto är @sertalpbilal.
Men nog snackat om honom. Åter till Allsvenskan och Allfalytics. Som du säkert förstår är modellens förväntade poäng ingen absolut sanning, så hur hur gick det då? Dags för lite grafer!
 Efter en tung start kom laget igång lagom till vecka 8 och mellan frikorten i vecka 9 och vecka 20 knappade modellen in på topp 1000 och höll jämn takt med topp 100. Besara lämnades sedan utanför frikortet och efter två horribla veckor i 25 och 26 var säsongen över.
Efter en tung start kom laget igång lagom till vecka 8 och mellan frikorten i vecka 9 och vecka 20 knappade modellen in på topp 1000 och höll jämn takt med topp 100. Besara lämnades sedan utanför frikortet och efter två horribla veckor i 25 och 26 var säsongen över.
Att modellen tappar direkt vid starten är i sig inte oväntat. Dels flyger det väldigt många chip de första veckorna, men sen har modellen också sin svåraste period från början. Vissa spelare och klubbar är nya i ligan. Andra har bytt klubb. Någon har fått en helt ny roll i truppen. Modellen är långsammare än du och jag på att plocka upp den typen av info. Det är också just i början som det är svårast att uppskatta speltiden för varje spelare, något som är erkänt svårt i allmänhet och som kan få ett väldigt genomslag på förväntade poäng.
Utvärdering av modellen
Även om det kanske är kul att se hur det går för ett lag som litar blint på modellen är det kanske inte nödvändigtvis det bästa sättet att utvärdera hur bra modellen faktiskt presterar. Mycket av prestationen kan härledas till min förmåga att estimera speltid, och den kan vara minst sagt svajig. Som tur är har vi ju nu ett facit på varje spelares exakta speltid i alla matcher under föregående säsong. Det betyder att vi kan köra om modellen på förra årets Allsvenskan men med rätt minuter på alla spelare. Då eliminerar vi en stor potentiell felkälla.
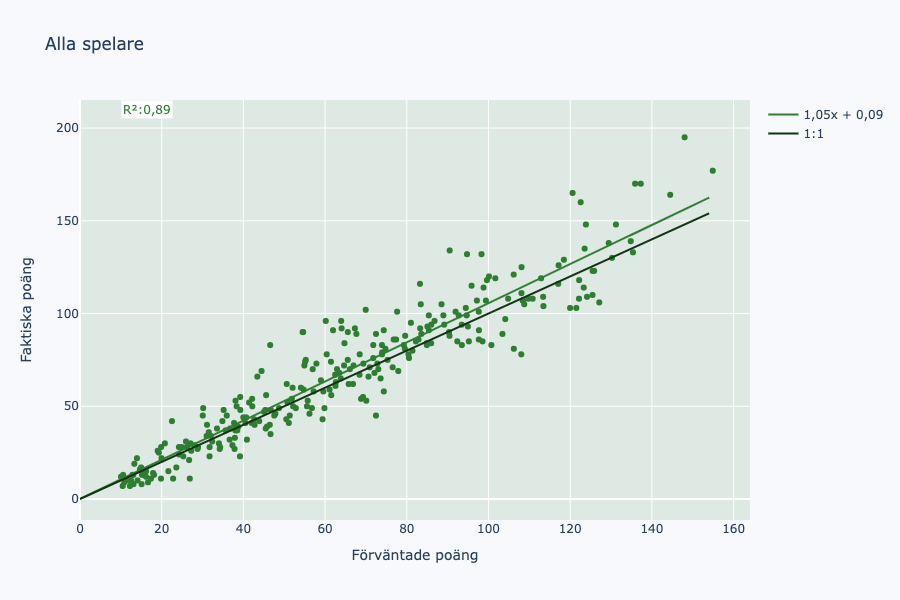
Här ser vi ett sambandsdiagram. Varje punkt representerar en spelares förväntade och faktiska poäng över 30 omgångar. Längst uppe till höger har vi Besara och Jeremejeff. Längst nere till vänster har vi några spelare jag aldrig har hört talas om. Den svarta linjen representerar ett 1:1-förhållande. Alla spelare över linjen har presterat bättre än modellen förutspått och det motsatta gäller för spelarna som befinner sig under linjen. Den gröna linjen är en så kallad “line of best fit” - en linje som minimerar distansen mellan punkterna och linjen. Vi vill ligga så nära 1x + 0 som möjligt. 1,05x + 1,67 antyder att modellen tenderar att undervärdera poängskörd något. I övre vänstra hörnet syns R², ett värde som anger hur stor del av Y (faktiska poäng) som förklaras av X (modellens förväntade poäng). Vi vill ligga så nära 1 som möjligt, och vårt värde på 0,89 får anses bra.
Men vi kan ju enkelt se att den verkar undervärdera bra spelares poängskörd mer än dåliga. Vad beror det på? Vi börjar med att dela upp det per lagdel och vi börjar med det tråkigaste, målvakterna.
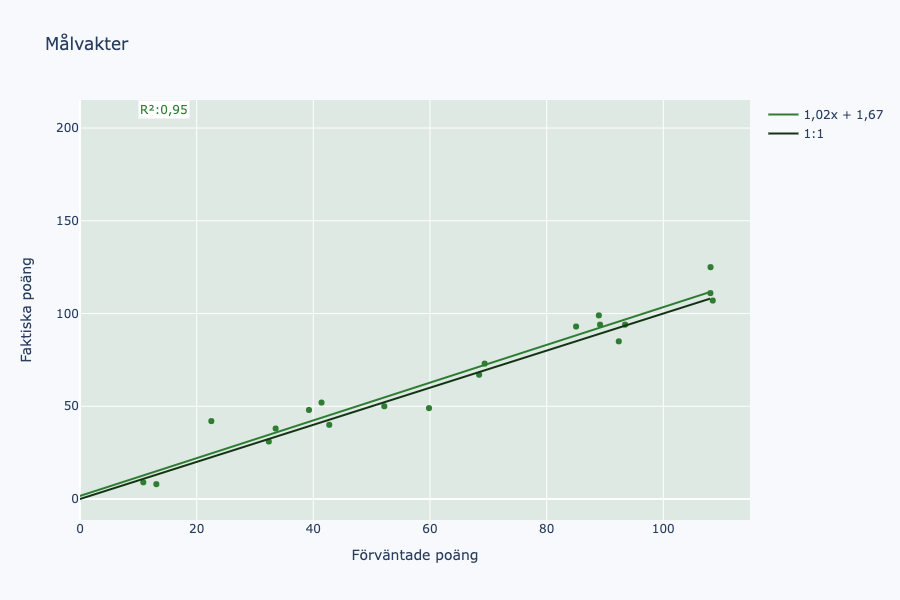
Ingenting konstigt här egentligen. Något undervärderad, men jag råkar också veta att körningen på föregående säsong saknar räddningspoäng. Vi hoppar uppåt ett steg i banan.
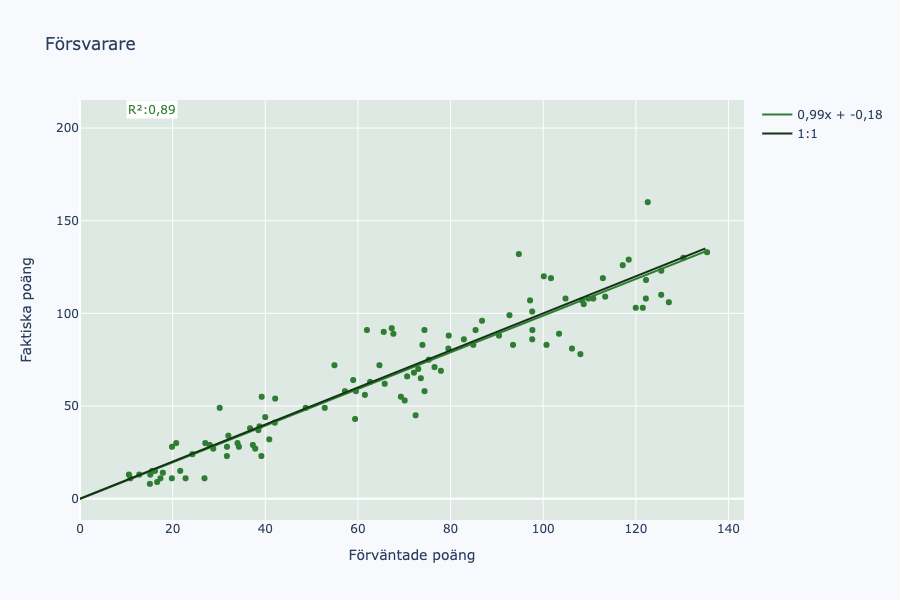
Här är vår “line of best fit” i princip ovanpå vår 1:1-linje. Vi har några spelare som sticker ut på båda sidor, vilket är ganska förväntat. Någon överpresterar. Någon annan underpresterar. Vidare mot mittfältet.
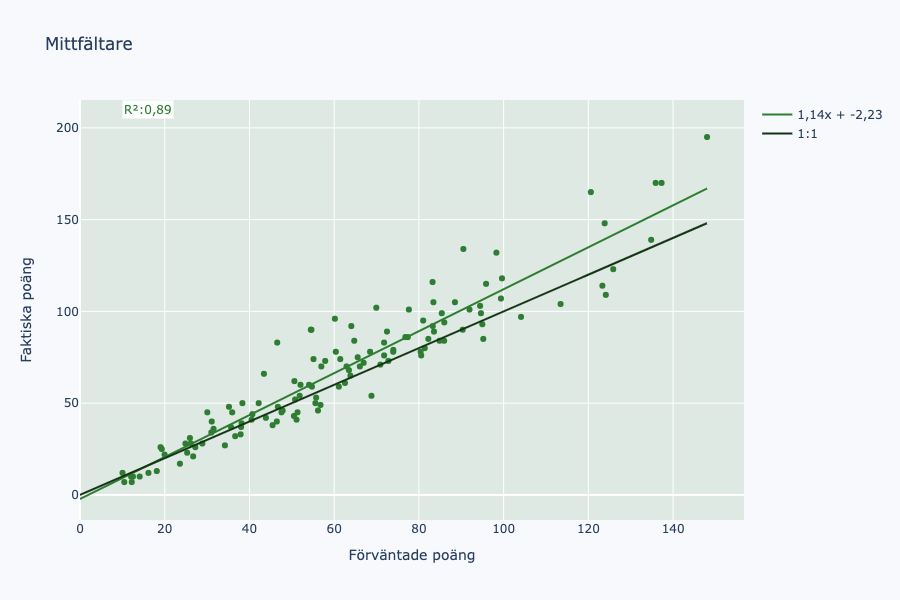
Nu ser vi en ganska tydlig skillnad. Modellen verkar klart ha undervärderat mittfältares poängskörd, i snitt ungefär 14%. Vi ska titta närmare på vilka spelare som sticker ut och kanske försöka gissa oss fram till varför alldeles strax, men först har vi en sista lagdel kvar.
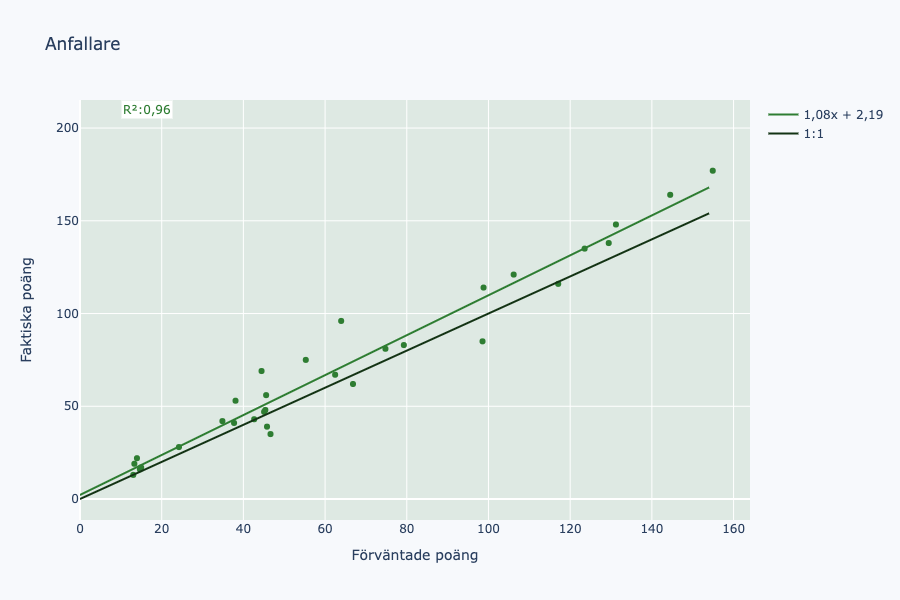
Även här underskattas poängskörden en del. Kanske är det målskörden som underskattas? Det skulle påverka både anfallare och mittfältare, men försvarare till mindre grad. Vi tittar närmare på olika spelare som under- respektive överskattas.
Överskattade spelare
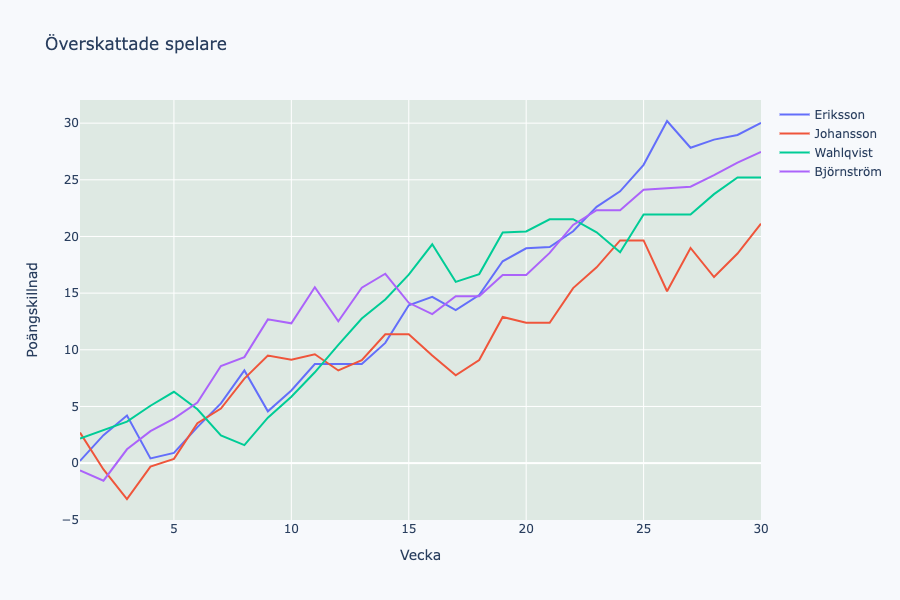
Här ser vi en komplett lista över alla spelare som modellen överskattade med minst 20 poäng föregående säsong. Alla fyra är backar vilket direkt känns underligt. Om vi inkluderar alla spelare som överskattades med minst 15 poäng får vi in modellfavoriten Magashy som ensam mittfältare bland 13 backar. Ytterligare bevis för modellens underskattning av offensiva spelare.
Underskattade spelare
För att undvika alltför grötiga grafer har jag valt att dela in de underskattade spelarna i tre kategorier.
- Spelare som underskattats tidigt där modellen senare under säsongen kommit ikapp och hittat ungefär rätt nivå.
- Spelare som haft ungefär rätt nivå initialt och sedan underskattats senare på säsongen.
- Spelare som underskattats genom hela säsongen.
Vi tar dem i tur och ordning.
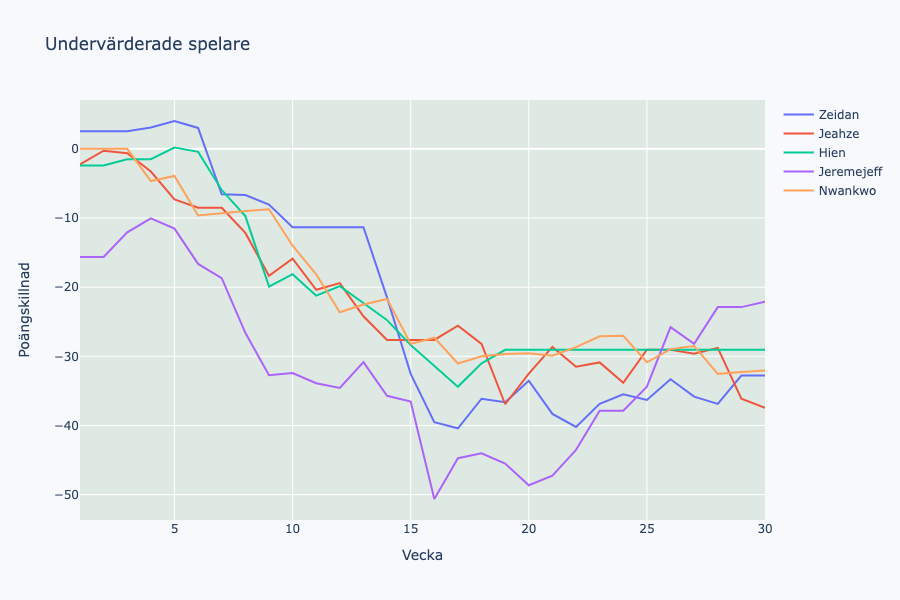 Vi kan egentligen ignorera Hien då han smög sig in här genom att säljas efter en kanonvår. Men om vi tittar på övriga spelare i den här gruppen så handlar det främst om spelare som gjorde en oväntat bra vår för att sedan svalna av och prestera på en mer normal nivå till andra halvan av säsongen. Jeremejeff gjorde tex 18 mål första 16 omgångarna följt av 4 de sista 14.
Vi kan egentligen ignorera Hien då han smög sig in här genom att säljas efter en kanonvår. Men om vi tittar på övriga spelare i den här gruppen så handlar det främst om spelare som gjorde en oväntat bra vår för att sedan svalna av och prestera på en mer normal nivå till andra halvan av säsongen. Jeremejeff gjorde tex 18 mål första 16 omgångarna följt av 4 de sista 14.
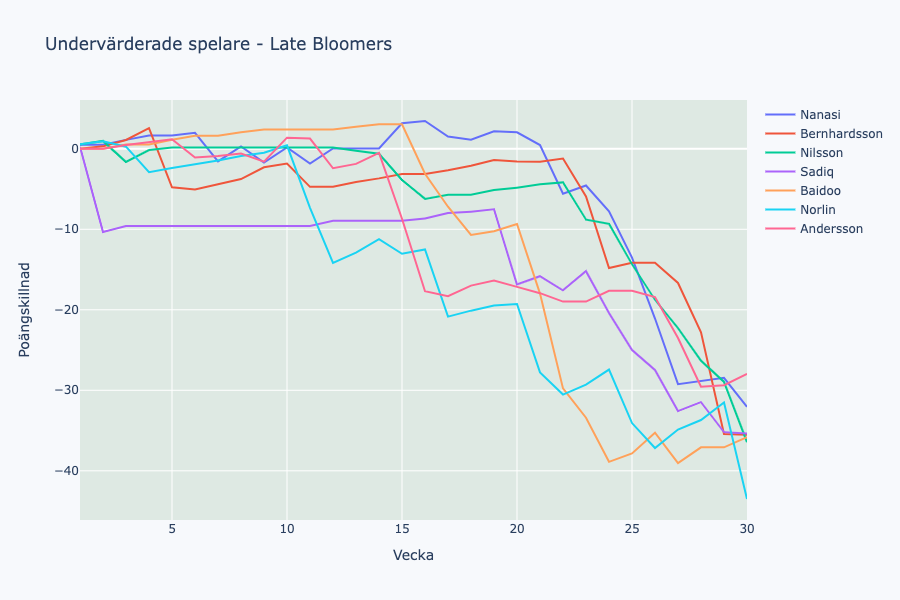 Här hittar vi en grupp av, ofta unga, spelare som hade begränsad speltid tidigt på våren för att sedan ta en ordinarie plats och explodera i produktion mot den senare delen av säsongen.
Här hittar vi en grupp av, ofta unga, spelare som hade begränsad speltid tidigt på våren för att sedan ta en ordinarie plats och explodera i produktion mot den senare delen av säsongen.
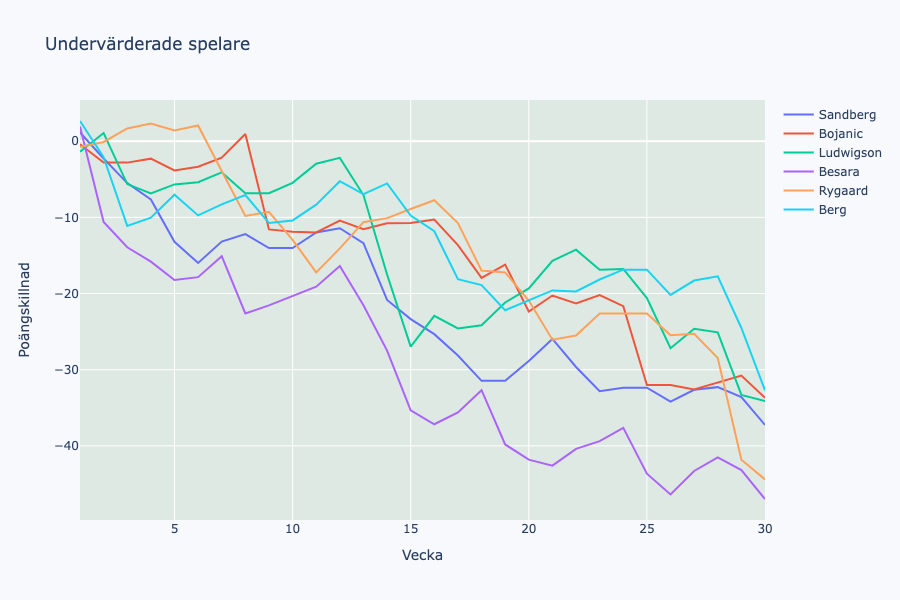 Avslutningsvis kommer de konsekvent underskattade spelarna, aka Hammarby med vänner. Konsekvent bra prestationer med ett litet undantag för Ludwigsson som var lite mer explosiv i sin poängskörd.
Avslutningsvis kommer de konsekvent underskattade spelarna, aka Hammarby med vänner. Konsekvent bra prestationer med ett litet undantag för Ludwigsson som var lite mer explosiv i sin poängskörd.
Summering
Det verkar som att modellen saknar en del mål vilket leder till lägre förväntade poäng för primärt mittfältare och anfallare, men också eventuellt högre förväntade poäng för backar och målvakter. Jag behöver titta närmare på vad det beror på. Det är dock någonting att ha i åtanke framöver, att modellen tenderar att underskatta offensiva spelare. Tidigare observerade vi att bättre spelare verkade undervärderades mer än sämre spelare, men när vi bryter ner det per lagdel kan vi se att det förklaras av att mittfältare och anfallare undervärderas mer och tar fler poäng. Samtliga lagdelar har ett R²-värde kring eller klart över 0,9 vilket antyder ett tydligt samband mellan modellens förväntade poäng och det faktiska utfallet.